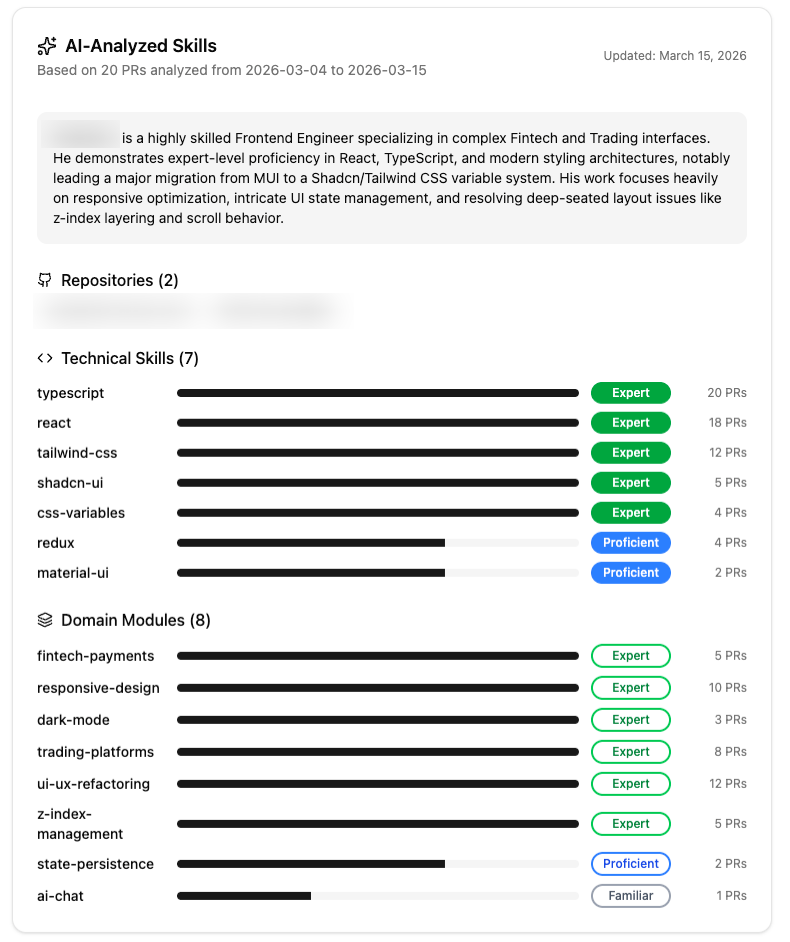
Semantic Search at Scale: Inside Document Intelligence's Multi-Format Processing Engine
Knowledge workers spend a significant part of every day searching for information. Across documents, emails, shared drives, and old folders. Most enterprise search tools use keyword matching, which means if you do not remember the exact term used in the document, you will not find it. That time is wasted, every day, across your entire team.
We built Document Intelligence to fix this.
The Problem
Due diligence teams drown in documents. A single deal might involve PDF contracts, Word documents, Excel financial models, PowerPoint decks, email archives, and scanned paper documents. Each format needs a different tool to open. None of them talk to each other. And when someone asks "what is our liability if the project is delayed?" nobody can answer without manually digging through hundreds of files.
Keyword search does not help here. If the answer lives in a force majeure clause that never uses the word "delay," keyword search returns nothing. The information exists in your organization. You just cannot find it.
This is not a search problem. It is a comprehension problem. Your tools can match words. They cannot understand meaning.
What We Built
Document Intelligence has two parts: a processing pipeline that handles any document format, and a search layer that understands meaning.
Multi-Format Processing: The system ingests PDFs (native and scanned), Word documents, Excel spreadsheets, PowerPoint presentations, emails, images, plain text, CSV files, and more. Each format has a dedicated extraction module. Scanned documents go through OCR with custom Arabic language models. Tables are detected and structured. Metadata is preserved. Everything is converted into searchable, structured content.
Semantic Search: After extraction, the content is embedded using a model we fine-tuned on a large corpus of query-document pairs from financial services, legal, and real estate domains. When you search for "what is our liability if the project is delayed?" the system returns the force majeure clause from the construction contract and the delay penalty section from the SLA -- even though neither document contains your exact query terms. It understands what you are asking, not just the words you used.
Entity Extraction: Beyond search, the system automatically identifies and extracts structured data from documents -- monetary amounts, dates, company names, party names, obligations, property addresses, and more. These entities are linked into a knowledge graph, enabling queries like "show me all contracts signed by Company X in 2025."
Why We Built This
Every organization we work with has the same problem: the information exists, but nobody can find it fast enough. People resort to asking colleagues, re-reading entire documents, or just guessing. That is wasted time and wasted expertise.
We built Document Intelligence because search should work the way people think -- by meaning, not by exact keyword match. And because document processing should be invisible. You should not need to care whether something is a scanned PDF or a Word document or an email attachment. The system handles all of that so your team can focus on the actual work.
This system is in production across multiple client organizations. It processes documents at scale, handles Arabic and English text, and returns results fast enough that people actually use it instead of going back to manual search. The teams using it have recovered meaningful hours every day that were previously lost to information retrieval.
Who This Is For
If your team works with large document collections -- legal, compliance, real estate, financial services, due diligence -- and people spend meaningful time searching for information they know exists somewhere, Document Intelligence eliminates that friction.
To request a proof-of-concept with your own documents, contact info@salem.ventures.